1. Executive Thesis
In one of ToastDeck's early field observations, an AI system was asked to recommend trusted providers in a service category. The system correctly identified a national platform operating in that category, described it accurately, and placed it in the right industry. Then it weakened the recommendation with a caveat. The hedge was not a hallucination. The system had interpreted the business correctly — and that very correctness softened the recommendation.
The hedge in that observation was not random. The model had sufficient evidence to recognize the provider — but insufficient evidence to recommend it without qualification. The likely causes are familiar to anyone who has diagnosed a B2Ai failure: a thin corroboration graph, inconsistent category signals across platforms, or a representation that described the business accurately but not specifically enough to justify confidence against better-attested competitors. The caveat was not a malfunction. It was the model doing exactly what it is designed to do — expressing calibrated uncertainty when the evidence does not support a clean recommendation. That is why visibility alone is not enough. A business can be known and still be passed over, not because the model cannot find it, but because the model cannot sufficiently justify it.
The urgency of the B2Ai thesis is compounded by the directional shift from conversational AI to agentic AI. In conversational interfaces, a user asks a question and the AI generates an answer — the human still clicks, calls, or decides. In agentic interfaces, the AI is given a task and executes it: book the service, route the order, find and contact the provider, complete the transaction. In that environment, the human may never evaluate the shortlist. The model selects, acts, and the business either receives the customer or does not. The B2Ai thesis is relevant now, before the conversational phase ends, because the selection conditions being established today — which entities the model knows, trusts, and can justify — are the same conditions that will govern agentic routing tomorrow. Businesses that address the recognition-to-selection gap now will be positioned for the agentic environment. Businesses that wait until agents are the norm will be correcting a deficit that has already compounded. Even before full agentic commerce matures, the same selection conditions already shape AI-generated recommendations today; the agentic shift extends the argument's urgency but is not its only proof.
Businesses are entering a new commercial environment.
For the last two decades, the dominant question was whether a business could be found by people through search, social platforms, directories, marketplaces, paid ads, and content discovery. That question still matters. But it is no longer sufficient.
AI systems are becoming commercial intermediaries. They do not merely retrieve links; they interpret a business, weigh it against competitors, summarize its reputation, and decide whether to recommend it. Sometimes they hedge that recommendation. Sometimes they leave the business out of the answer altogether.
That shift creates the need for a new commercial layer: B2Ai — Business-to-AI. The emerging upstream layer where businesses must become legible, trustworthy, and selectable to AI systems before they are presented to humans, agents, or downstream decision workflows.
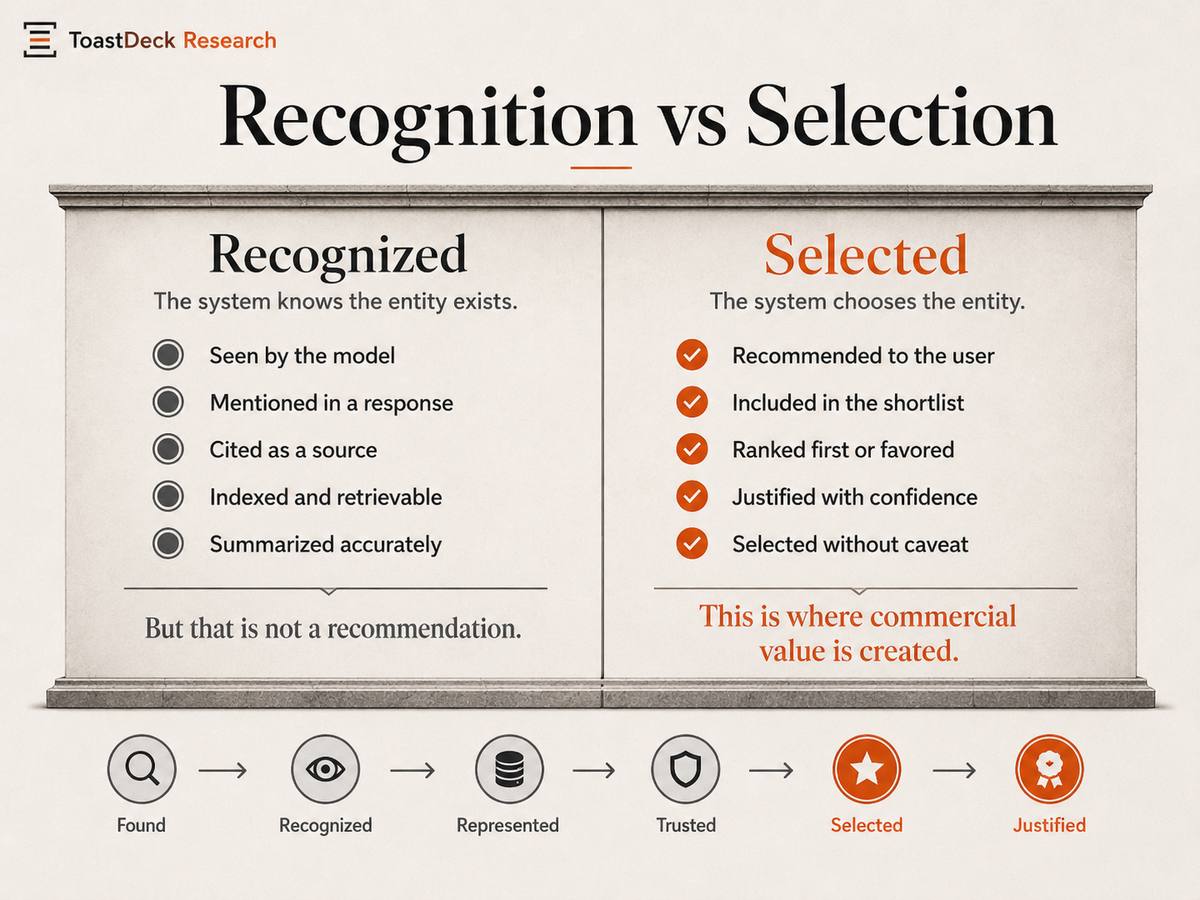
The central thesis is: Recognition is not selection.
The AI system may know that a business exists and still not recommend it. A business may be visible but not chosen. A company may appear in a response but be hedged, caveated, misunderstood, miscategorized, displaced by competitors, or excluded when the model must make a recommendation.
That difference between being known and being selected is the business gap B2Ai is built to study.
2. From Visibility to Selection
Traditional search created a ranked-choice environment. A user searched. A platform returned a list of links. The user evaluated options, clicked, compared, and decided. In that environment, visibility meant appearing where the user could find you.
AI systems change the shape of the decision environment. A user may ask:
- Who is the best senior care provider near Cleveland?
- Which insurance company is most trustworthy for small business coverage?
- What law firm should I contact for this type of issue?
- Which product is best for this use case?
- Compare these providers and recommend one.
- Find me a local company that can handle this.
The AI system does not only retrieve. It interprets the task, judges which entities are relevant, and weighs the signals it can find before selecting what the user sees.
That means businesses are now competing inside an AI-mediated selection process. The user rarely sees the full candidate environment, and almost never learns which entities were left out or why one was chosen over another. The AI system becomes a selection intermediary.
This creates a new set of business risks:
- The AI recognizes the business but does not select it.
- The AI selects a competitor instead.
- The AI describes the business inaccurately.
- The AI confuses the business with another entity.
- The AI adds caveats that weaken trust.
- The AI cannot justify the business clearly.
- The AI lacks enough corroborating evidence to recommend the business confidently.
- The AI treats the business as generic even when it has specific expertise.
The new commercial problem is not merely ranking. It is representation, trust, selection, justification, and the resolution of ambiguity.


3. Recognition Is Not Selection
Recognition means the AI system knows an entity exists. Selection means the AI system chooses, recommends, includes, ranks, compares, or justifies the entity in response to a user's request.
These are different outcomes.
For the purposes of this thesis, selection encompasses any AI system output that routes, recommends, ranks, or delegates to a specific external entity in response to a user's decision context. This includes: a direct recommendation in a conversational interface ("I recommend X for this"); inclusion in a short list returned to a user making a comparison decision; priority routing by an agentic system executing a task on the user's behalf; and preference assignment in an automated workflow where the model must choose between competing providers. The common property across all of these is that the model is making or shaping a consequential choice, not merely surfacing information. Different interfaces trigger selection differently — a chat assistant weights narrative justifiability, an agent weights API reliability and transactability, a comparison surface weights structured attribute matching — but the underlying condition is the same: the model is committing to an entity rather than presenting options for the human to evaluate.
A business can be recognized but not selected. A brand can be described accurately but not recommended. A company can appear in an answer and still be known without being trusted enough to win the recommendation.
The distinction matters because AI systems compress the field of choice. In traditional search, being on the first page may still create opportunity — the user can scan multiple options. In AI-generated answers, the system may return a single recommendation, a short list, or a summary that frames the user's entire perception.
The business that is selected receives disproportionate attention. The business that is omitted may never enter the decision.
This is the core B2Ai problem: the commercial value does not come from recognition alone. It comes from being selected under model constraints. ToastDeck's research focuses on that gap.
3.1 Formal Grounding: Recognition ≠ Selection
Recognition ≠ Selection is not just a slogan. It maps onto the candidate-generation-versus-ranking architecture of large-scale recommender systems — an architecture that applies directly to AI answer engines and business selection.
Covington, Adams, and Sargin's 2016 YouTube recommendations paper frames its system as what the authors call the classic two-stage information retrieval dichotomy: a candidate generation model followed by a separate ranking model.1
B2Ai applies that architecture to business selection, but decomposes the admission problem more finely. In recommender systems, candidate generation often bundles together retrieval, availability, and candidate admission into one stage. In B2Ai, Layer 0 handles the machine path to the entity: can the system reach it, parse it, and find it? Recognition then asks whether the system correctly identifies and resolves the entity once it is available as a candidate.
Selection corresponds to the ranking problem: among available and recognized candidates, what gets surfaced, recommended, routed to, or chosen under constraint?
Recommender-systems research also supports the consequence of candidate-set composition. Bower et al. study two-step recommender systems where ranking is applied only to the already-produced candidate set, showing that candidate-set imbalance shapes downstream exposure outcomes.2 The keystone for the Recognition ≠ Selection distinction is Covington; Bower supports the consequence.
The same two-stage structure is now visible from the practitioner side as well. Generative-engine-optimization practitioners increasingly describe AI answer engines as running retrieval-augmented generation in two steps — a retrieval step that pulls candidate sources from an index, followed by a generation step that synthesizes those sources and chooses which to attribute. That the recognition-vs-selection split arises independently in both the academic recommender-systems literature and applied GEO practice strengthens the claim that it is a real structural property of these systems, not a framing peculiar to this thesis.
A common objection to the B2Ai thesis is that AI systems are stochastic and constantly updated — so how can a business reliably engineer selectability? The answer is that B2Ai does not claim to guarantee selection. It claims that the conditions which make selection more probable are knowable, testable, and improvable. The goal is not to control the model. The goal is to ensure the entity's ground truth — its actual identity, category, location, credentials, and corroborating evidence — is legible, consistent, and well-sourced enough that the model can justify a recommendation when the query warrants one. A business that is ambiguous, inconsistently represented, or poorly corroborated gives the model a reason to hedge or displace. A business that is clear, consistent, and well-attested gives the model what it needs to select confidently. That is not gaming the system. That is meeting the system's evidentiary standard.
4. B2Ai in Context
B2Ai means Business-to-AI. It describes the commercial relationship between businesses and AI systems that interpret, represent, recommend, exclude, or transact with them. ToastDeck does not claim to have coined B2Ai; this thesis focuses on the upstream selection layer within the broader Business-to-AI commerce shift.
B2Ai is not a replacement for B2B or B2C. It is a layer upstream of both. Before a customer sees a business through an AI system, the AI system must first form a representation of that business. If that representation is weak, inconsistent, outdated, or ambiguous, the business may lose selection before the human buyer ever evaluates it.
B2Ai in relation to SEO, GEO, and AEO
SEO handles search visibility — whether a business appears in ranked results. GEO and AEO address answer-surface visibility — whether a business appears in AI-generated answers, citation surfaces, and answer engines. That work matters and remains foundational for the platforms that operate within its scope.
B2Ai studies the upstream cross-system layer: how AI systems form business representations, and how they use those representations to compare, justify, caveat, and ultimately select or exclude an entity across multiple systems at once. A business can appear in AI-generated answers — visible, cited, present — and still fail the B2Ai test.
The two-layer environment
In May 2026, Google published official guidance stating that optimization for generative AI features in Google Search remains continuous with traditional SEO.34 Google explicitly frames GEO and AEO as still SEO from Google Search's perspective, and names tactics site owners can ignore for Google Search: llms.txt files, chunking content, AI-specific rewriting, inauthentic mentions, and special schema for generative AI search.
That position is important, but it is bounded. Google's guidance applies to Google Search experiences. It does not resolve the broader multi-system environment in which businesses are interpreted, compared, selected, caveated, excluded, or eventually transacted with by AI systems across ChatGPT, Claude, Perplexity, Gemini, Meta AI, Grok, vertical assistants, browser agents, and emerging agentic interfaces.5
The market is therefore splitting into two related but distinct layers. Layer one is platform-specific AI search optimization — for Google Search, the answer is still SEO. Layer two is cross-system AI interpretation and selection — this is the layer B2Ai studies.
Why selection is commercially meaningful
Google has clarified that its spam policies apply to generative AI responses in Google Search, including attempts to manipulate AI-generated responses.6 That clarification confirms that AI-generated recommendations are now commercially important enough to require explicit anti-manipulation enforcement.
In 2026, Google removed AI Overviews for specific health-related queries following an external investigation into misleading medical summaries.7 The important point is not that Google removed an entire health category. It is that the platform selectively intervened when generated answers created unacceptable risk in a sensitive domain. AI selection has become commercially meaningful.
Published research reinforces the instability of the current environment. A 2023 Stanford-affiliated study of four generative search engines found that on average only 51.5% of generated sentences were fully supported by their citations and only 74.5% of citations supported their associated statements.8 A 2026 Yelp / Morning Consult survey of 2,202 U.S. adults found that while 65% had used an AI-powered search tool in the prior six months, only 15% trusted that information "a lot," 63% double-checked AI search results against other sources, and 72% said AI platforms should always show where their information comes from.9
Related work and market position
AI-visibility monitoring tools. A growing set of commercial products — among them Profound, Brandlight, and the AI-visibility features now offered within established SEO platforms such as Ahrefs, Conductor, and others — measure whether and how often a brand appears in AI-generated answers across systems. This is recognition measurement. B2Ai asks the next question: when a user requests a recommendation, is the entity selected, caveated, displaced, or excluded, and which upstream condition explains the outcome.
Reputation and review platforms. Platforms oriented around reviews and reputation increasingly report on AI-surface presence. Their signal feeds Authority Resolution (Layer 4) but is one input among several; B2Ai treats reputation as a contributor to authority, not as the selection outcome itself.
GEO/AEO consulting and content tooling. Generative- and answer-engine-optimization practice focuses on producing content and structure that improves answer-surface visibility. B2Ai is the cross-system layer above it: how representations form, compete, and resolve to selection across systems no single optimization program controls.
Mapping GEO/AEO tactics onto the B2Ai layers
The peer-reviewed root of the field is the Princeton GEO study, which found that a small set of content modifications can raise citation visibility by roughly 30–40%, with the strongest being the addition of citations, credible quotations, and verifiable statistics.10
Where each proven tactic lives in B2Ai. Statistics, citations, and credible quotations strengthen Layer 4 (Authority Resolution). Answer-first structure, comparison tables, and FAQ formatting strengthen Layer 2 (Representation) and the discovery-citation function of 0C. Schema markup and clear entity identity serve Layer 1 (Recognition) and Layer 2. Cross-platform presence is a Layer 3 (Consistency) tactic. Recency and active updating serve Layer 7 (Monitoring/Freshness).
Why the tactics are necessary but not sufficient. Most of the tactics above primarily optimize recognition-side conditions. The B2Ai claim is that they are not sufficient: an entity can execute every GEO tactic, become highly citable, and still lose the recommendation when the model must choose under constraint — because selection (Layer 5) is governed by competitor justifiability, ordering effects, and trust calibration that citation-optimization does not address. Recognition is not selection.
5. Selection vs. Substitution
Substitution does not describe a degraded selection outcome; it describes the disappearance of the selection event itself. B2Ai studies how AI systems interpret external entities, weigh them against one another, and decide whether to recommend, caveat, exclude, or transact with them inside commercial workflows. In some cases, however, the AI system no longer needs an external entity for a specific task layer of the workflow; at that point the commercial problem changes from selection to substitution.11
Selection occurs when the AI system mediates between competing external entities. Substitution occurs when the AI system performs the task directly rather than selecting a provider to perform it. The distinction is task-specific, not category-specific: AI systems rarely replace entire businesses at once; they absorb discrete functions, outputs, or workflow layers while surrounding layers remain dependent on external parties.12
The deciding variable is accountability: if the model can itself become the accountable party for the deliverable (execution, warranty, liability, compliance, continuity), it substitutes; where it cannot, it must still select. This accountability axis explains why substitution appears first in narrow, digitally native, low-liability tasks and remains constrained in trust-sensitive, regulated, relational, or physical-world domains.
6. Operating Layers: The Eight-Layer Framework
ToastDeck's working model separates B2Ai into operating layers. These layers are not final doctrine. They are a research structure for studying how AI systems interpret and select entities.
Layer 0 — Machine Path Layer (Access, Ingestibility, Discovery)
Layer 1 — Recognition / Existence Resolution
Layer 2 — Representation
Layer 3 — Consistency
Layer 4 — Authority Resolution
Layer 5 — Selection Behavior
Layer 6 — Justification / Output Mediation
Layer 7 — Monitoring / Freshness / Re-grounding
The boundaries are drawn to be diagnostically separable: a failure isolated to Layer 0 (blocked access) has different causes, owners, and remedies than a Layer 5 selection displacement, and the value of the structure is that it tells a diagnostician which kind of failure they are looking at.
An important boundary on what these layers claim. The eight layers are not a claim about the internal architecture of any AI system. ToastDeck does not assert knowledge of how OpenAI, Google, Anthropic, or any provider internally retrieves, ranks, or selects entities. The layers are diagnostic layers: a model of observable failure modes and their distinct causes, owners, and remedies. They describe outcomes that can be measured from the outside, not mechanisms inferred about the inside.
A note on "resolution." Resolution is an act that occurs at several layers, not a standalone layer. Entity resolution occurs in Layer 1; authority resolution occurs in Layer 4; selection resolution occurs across Layers 5 and 6. The word remains in the framework; it is not counted as its own layer.

Layer 0The Machine Path Layer
The operating layers above Layer 0 begin with Recognition — whether an AI system correctly identifies an entity. Those layers carry an unstated assumption: that the entity's own surfaces — its website, its pages, its self-published evidence — can be reached, read, and found by the systems forming the representation.
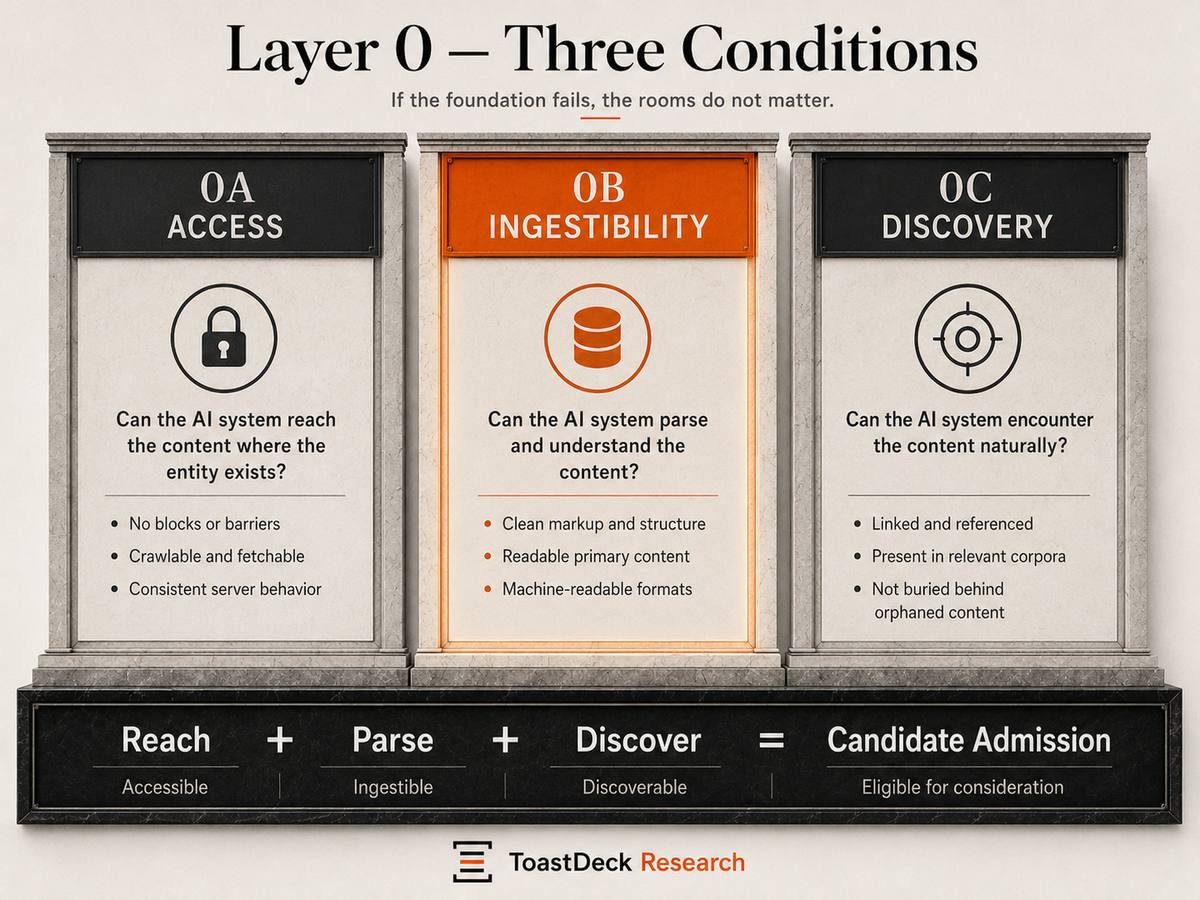
That assumption does not always hold. Before recognition, representation, authority, or selection can be assessed, an entity must pass three co-equal pre-selection conditions. Layer 0 asks: when a machine seeks this entity, can it reach the surface, parse the surface, and find the surface as a candidate?
Layer 0 is the only layer in the framework that is falsifiable before it is interpretive. It makes testable predictions that single observations can confirm or disconfirm. For that reason, the three Layer 0 conditions must be diagnosed before scoring the higher layers. If Layer 0 fails, the system may still know the entity through third-party sources — directories, reviews, knowledge panels, or prior training data — but the entity loses control over its own primary evidence, and any assessment based on its self-published surfaces begins from a false premise.
0A — Access
Access asks whether the requesting system is permitted to retrieve the entity's surfaces at all. Modern sites increasingly sit behind infrastructure intermediaries — content delivery networks, web application firewalls, and bot-management layers — that decide which automated clients may retrieve a page.
This is no longer an edge case. On July 1, 2025, Cloudflare announced a permission-based default for AI crawler access on new domains, requiring site owners to choose whether AI crawlers may retrieve their content.13 Cloudflare's own measurements put OpenAI's crawl-to-referral ratio at roughly 1,700 to 1 and Anthropic's at roughly 73,000 to 1 as of mid-2025.14 Infrastructure providers now offer per-crawler allowlists, purpose declarations, and paid-access flows as opt-in controls.1516
Diagnostic signature — 0A. Access Exclusion returns full content to an ordinary browser request but a refusal specifically to a request identifying as an AI crawler. It is detected only by varying the requesting identity.
0B — Ingestibility
Ingestibility asks whether, once a surface is reached, the meaning actually arrives in a form the consuming system can parse without executing code. The operating question is prior to quality and prior to recognition: When a machine requests this entity's primary surfaces, does the meaning arrive in the response itself, or only after a program runs?
The mechanism: client-side rendering and the rendering gap. In client-side rendering, the initial response is a near-empty shell plus a script bundle; the content is assembled afterward by executing that script in a browser. A 2024 study by Vercel and MERJ found that none of the major AI crawlers it measured render JavaScript — including OpenAI's crawlers, Anthropic's ClaudeBot, Meta's external agent, ByteDance's Bytespider, and PerplexityBot.17 The failure is specific to client-side rendering: content that resolves only in the post-execution document.18
Independent practitioner testing has documented this signature in the field. In a 2025 case study, ChatGPT, Perplexity, and Claude each failed to retrieve the site's content and in several instances stated explicitly that the content could not be read because it required JavaScript.19 Affected URLs were demoted, pushed to non-primary citation surfaces and stripped of snippets.20

Diagnostic signature — 0B. Substrate Invisibility returns a 200 response with an empty or shell document to every client. Detected by reading the body: the entity's own site, viewed as raw HTML before script execution, returns little or no substantive content.
0C — Discovery
Discovery asks whether the entity surfaces as a candidate at all — whether it can be found, crawled, indexed, or retrieved into the candidate environment before recognition begins. A surface can be both reachable (0A) and parseable (0B) and still never be discovered as a candidate.
Layer 0C uses discovery citations, not authority citations. A discovery citation helps a machine system find, crawl, index, or retrieve an entity. An authority citation helps justify why an entity should be trusted, cited, recommended, or selected in an answer. Same surface form, different function, different layer.
Discovery operates through more than one pathway: maintained index, live search queries, link and citation graph traversal, and query fan-out. An entity can be discoverable along one pathway and absent from another. This is why Discovery is a condition in its own right and not a restatement of Access.
Why Layer 0 is a B2Ai concern and not merely a technical SEO note
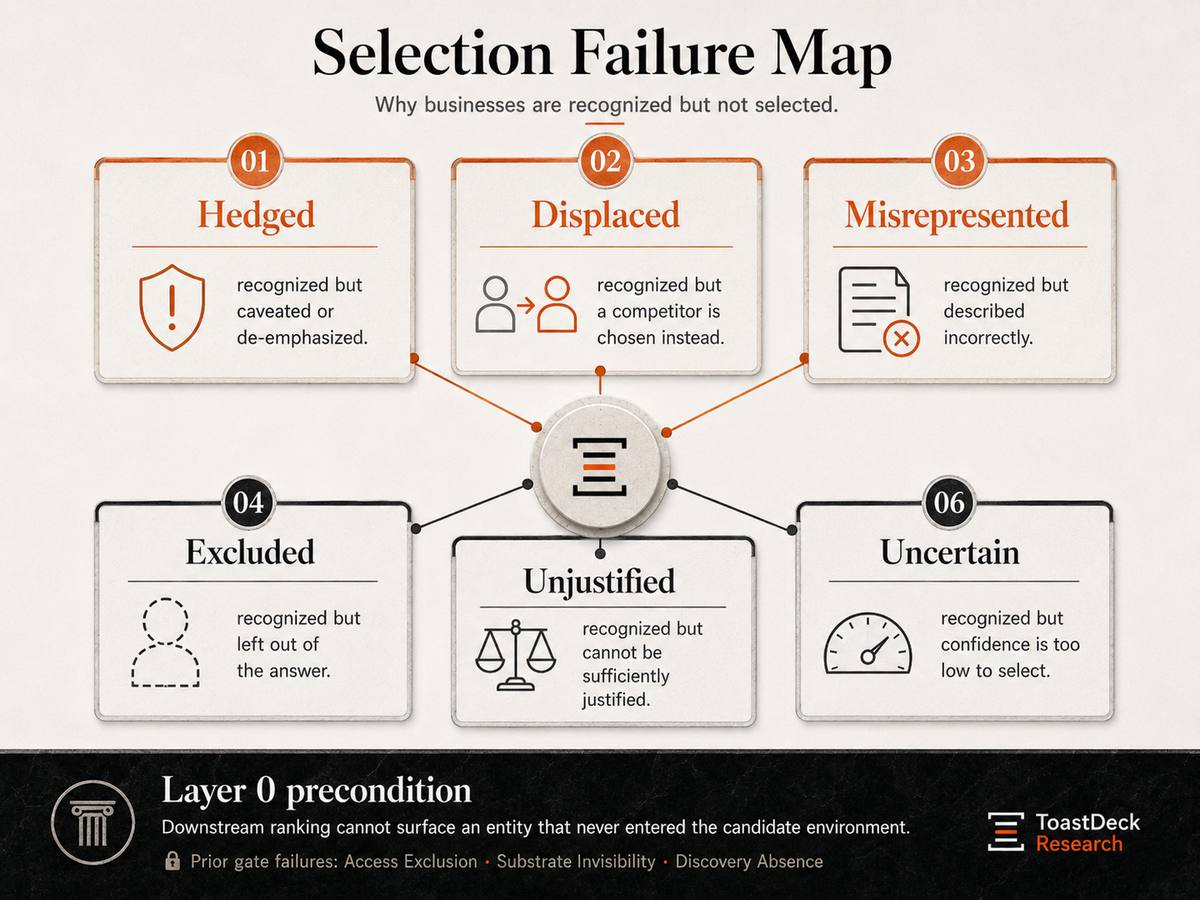
The Machine Path Layer is not a tactic; it is the substrate on which every higher layer depends. When an entity's own surfaces are unreachable, unreadable, or undiscoverable, the entity surrenders the one input over which it has full control — its own framing, its own claims, its own specific differentiation — and cedes its representation entirely to third-party sources. This makes the Machine Path Layer an upstream cause of failure modes including generic description, Category Drift, Location Drift, and Competitor Displacement.
A necessary boundary on the evidence: the principal measurement is vendor-affiliated research.21 The methodology is nonetheless sound and the sample large — over a billion crawler fetches — and the underlying measurement is a factual observation independent of the recommendation drawn from it. The rendering gap documented in 2024 has been corroborated in independent practitioner testing through early 2026,22 but is subject to change and belongs to Monitoring (Layer 7) as much as to a one-time audit. Browser-based agents may not share this gap.23
Layer 1Recognition / Existence Resolution
Does the AI system correctly identify what the entity is, and resolve it as the intended business, source, or organization? This is the baseline interpretive layer. Discovery (0C) means the entity can be found as a candidate; Recognition means the system correctly understands what the candidate is. If the entity is unknown or misresolved — confused with another entity, or identified as the wrong thing — it cannot be accurately represented or selected.
Layer 2Representation
How does the AI system describe the entity? This includes name, category, location, services, products, affiliations, reputation, and role in the market. Recognition asks "what is it?" Representation asks "how is it described?" Representation errors include: wrong category, wrong location, wrong services, wrong ownership, wrong credentials, outdated information, competitor confusion, and generic or incomplete descriptions.
Layer 3Consistency
Is the entity represented consistently across AI systems, prompts, and retrieval conditions? An entity may be described one way by ChatGPT, another way by Claude, another way by Gemini, and another way by Perplexity. Model disagreement is not noise. It is a signal of representation instability.
Layer 4Authority Resolution
Which sources, claims, entities, or signals does the AI system treat as trustworthy when forming an answer? Authority may come from: official website clarity, schema, reviews, listings, directories, third-party mentions, press, institutional signals, and source consistency. Representation describes the entity; Authority Resolution decides what should be trusted about it relative to competing signals. Authority is not just "popularity." It is the model's ability to justify why this entity belongs in the answer.
Authority signals are not uniform in kind. For diagnostic and remediation purposes, B2Ai separates them into two classes. Verifiable signals are deterministic facts the model can confirm or falsify against structured sources: business registration, licensed credentials, physical address, service area, accreditation, years in operation, regulatory standing. These either resolve or they do not — they are treated under the deterministic Evidence Class. Subjective signals are probabilistic inputs that the model weights but cannot confirm: customer sentiment aggregated from reviews, brand tone inferred from content, perceived expertise derived from publication history, trust inferred from mention volume and source quality. These vary by source, recency, and retrieval context, and are reported under the probabilistic Evidence Class. The practical consequence is that conflicting signals — strong verifiable facts paired with weak or negative subjective signals — do not cancel each other out cleanly. A business with verified credentials and poor review sentiment may still receive a caveated recommendation, because the model's authority resolution is a weighted synthesis, not a binary pass/fail. Understanding which signal class is causing a selection failure determines the remediation path: verifiable failures require factual correction; subjective failures require sustained evidence accumulation over time.
Layer 5Selection Behavior
Does the AI system select the entity when the user asks a recommendation, comparison, or decision-oriented question? This is the core layer; the thesis is named for it. Authority Resolution is trust evaluation; Selection is the choice made after or during that evaluation. Trusted does not always mean selected.
The mechanism of selection instability. A 2025 study by Bito, Ren, and He provides the first in-depth investigation of position bias in LLM-based recommendation, reporting that LLM-based recommendation models are highly sensitive to the order in which candidate items appear in a prompt: minor changes in the appearance order of candidates can disproportionately change which entity the model recommends.24 The instability is architectural, not incidental.
The measurement method mirrors the B2Ai diagnostic approach. Bito et al. quantify position bias by generating a ranking from a shuffled candidate list, then a second ranking from a reversed list, and measuring the similarity between the two.25 A recommendation that depends on prompt serialization rather than the entity's merits is a recommendation a competitor can dislodge.
Layer 6Justification / Output Mediation
When an AI system selects or excludes an entity, how does it explain, frame, support, caveat, or mediate that decision? A weak justification can reduce trust. A strong justification can increase conversion. A caveated justification may signal unresolved trust or quality concerns.
Layer 6 is also the accounting home for a distinction that spans the whole framework: whether a given selection failure is addressable by the entity or structural to the platform — arising from model priors, platform policy, retrieval design, or commercial incentives.2627
This layer is also where Source Boundary Failure mechanically occurs — the conflation of facts across sources during generation, in which the model attributes to one entity material drawn from an adjacent source.
Layer 7Monitoring / Freshness / Re-grounding
Does the entity's AI representation and selection behavior remain stable, current, and evidence-grounded over time? B2Ai is not a one-time audit problem. AI systems change. Sources change. Competitors change. Model behavior changes.
Freshness is grounded in the Temporal Information Retrieval literature. The canonical survey by Campos, Dias, Jorge, and Jatowt distinguishes recency-sensitive queries from time-sensitive queries with explicit temporal constraints.28 A 2025 worked example applies a recency prior to RAG retrieval, illustrating how a freshness term can be combined with relevance at retrieval time.29 Independent evidence also indicates that the substrate of AI answers is itself temporally unstable: cited web sources can become inaccessible or change after the fact, motivating longitudinal tracking rather than one-time audits.30
7. Diagnostic Architecture
Evidence Class: how findings are reported
Probabilistic findings are reported as distributions. Selection Behavior (Layer 5) does not resolve to a single value. The same entity, under the same query, can be selected in one run and not the next. Reporting any single run as "the" result is a category error. These findings are reported as distributions — across runs, orderings, competitor sets, platforms, and time — with their variability stated, not hidden.
Conflating the two classes is the most common way AI-visibility measurement misleads. A probabilistic selection result presented as a deterministic fact overstates a single favorable draw. The same result presented honestly — "the model selected you in 6 of 10 runs, displaced by a specific competitor in the other 4" — is both more truthful and more actionable.
Perturbation testing
Perturbation testing is the diagnostic method used to test whether selection behavior holds when surrounding conditions change. The core entity or decision question remains fixed while the test varies candidate order, competitor set, prompt framing, or comparison structure.
This method is grounded in LLM recommendation and evaluation research. Shi et al. extend the same concern into LLM-as-a-Judge settings, introducing repetition stability, position consistency, and preference fairness across pairwise and list-wise evaluations.31 Zheng et al. likewise document position, verbosity, and self-enhancement biases and recommend answer-order swapping as a mitigation.32
Entity-aware diagnostics
One mistake in the current market is treating every subject as a "brand." AI systems do not evaluate every entity through the same signal structure. A local business, product, person, organization, and brand each have different selection triggers, authority signals, representation risks, and resolution paths. The diagnostic layer identifies the type of entity and the selection problem.
The resolution discipline
Diagnosis exposes the recognition-to-selection gap; it does not close it. Closing it is a separate discipline: continuous, evidence-bound resolution as AI systems, sources, and competitors shift over time.
ToastDeck's resolution discipline is SOMAR: Selection, Output Mediation & Authority Resolution. In this thesis, SOMAR is treated as the operational bridge between diagnosis and evidence-bound correction. The proprietary operating methods are outside the scope of this paper. To be clear about what SOMAR is not: it does not prescribe manipulation of AI systems. It organizes evidence correction, authority strengthening, representation repair, and longitudinal monitoring around the specific failure layer a diagnosis identifies.
8. Field Study Foundation
ToastDeck's B2Ai thesis is not only theoretical. It is grounded in field-study work observing how AI systems represent and select entities across systems, industries, and prompts.
The first signed-consent case study supporting this research is Senior Sitters Club LLC, a pre-launch non-medical caregiver registry in Northeast Ohio. The Senior Sitters Club case predates the formal articulation of Layer 0. Its findings remain relevant to representation, selection, and failure-mode behavior, while substrate-level Machine Path diagnostics are now treated as a prior gate in the framework.
Field Study Snapshot: Senior Sitters Club LLC
The source audit was the VisibilityIQ Full Audit: Senior Sitters Club, generated May 8, 2026. The audit window was April 21–28, 2026. It ran 24 queries across ChatGPT, Claude, Gemini, and Perplexity, with each query executed five times to assess consistency.
Aggregate scores. Overall AI Visibility 64/100 (Mixed). Layer scores: Representation 75/100 (strongest), Selection 49/100 (weakest), Resolution 73/100.
The central finding. The clearest selection failure appeared in the category-level query "Best senior care providers in Cleveland, Ohio." ChatGPT consistently named Visiting Angels, Home Instead, and Comfort Keepers before Senior Sitters Club, in 5 of 5 runs. The dominant failure mode is therefore Recognized but Not Selected: the entity was known and describable, but competitors won the buyer-facing recommendation frame.
Distributional findings (reported per the Evidence Class rule). ChatGPT ranked the three national competitors ahead of SSC in 5 of 5 category-level runs. Claude framed SSC as a "sitting service" in 5 of 5 runs (Representation Instability: category wording weakening trust-sensitive positioning). Gemini relied on a Yelp-only citation pattern in 3 of 5 runs (Authority Displacement: a narrow citation graph). ChatGPT returned correct disambiguation in 4 of 5 runs and conflated the entity with an unrelated brand in 1 of 5 (a Recognition-layer instability). Perplexity returned stable service and service-area descriptions in 5 of 5 runs, the strongest baseline.
Industry research is also beginning to document the instability and platform divergence of AI visibility measurement. Birdeye's 2026 AI visibility research frames AI search visibility as cross-platform and affected by differences in how systems surface, cite, and recommend businesses.33

Observed failure modes
- Scale Inversion — A larger entity is disadvantaged because its self-published surface is unreadable to indexing systems.
- Location Drift — An entity is associated with the wrong city, market, headquarters, or service area.
- Category Drift — An entity is classified under the wrong or an overly broad category.
- Competitor Displacement — The AI system selects competitors not because the entity is unknown, but because competitors are easier to justify.
- Platform Caveat Penalty — Marketplaces or aggregators are described accurately but weakened by caveats such as "quality may vary by provider."
- Representation Instability — Different AI systems describe the same entity differently, revealing unresolved ambiguity.
- Substrate Invisibility — An entity is omitted or misrepresented because its primary self-published surface is unreadable to the systems forming the representation. Scoped to 0B.
- Access Exclusion — An entity's content is present and well-formed, but AI retrieval is denied by an infrastructure layer. Scoped to 0A.
- Discovery Absence — An entity is reachable and parseable but never assembled into the candidate environment. Scoped to 0C.
Correction Resilience and Source Boundary Failure
Source Boundary Failure occurs when the model attributes to one entity facts, claims, or identity drawn from an adjacent source, conflating two distinct things into one representation. This is documented in the source-attribution literature. A 2026 study measured that the factual accuracy of citations drops by approximately 42% on average as the number of tool calls scales from 2 to 150.34
First field instance. On June 1, 2026, a generative system conflated an unrelated commercial entity into its representation of this thesis, drawing identity material from an adjacent source rather than the canonical document. Under direct challenge, the system corrected cleanly. This is recorded as the first Source Boundary Failure observed and logged under this framework.
9. Trust-Sensitive Domains
B2Ai carries the highest stakes in industries where trust and accuracy are the product: insurance, healthcare, legal, finance, senior care, local service businesses, education, public-facing organizations, and products with safety, trust, or compliance implications. These industries cannot afford AI systems inventing or misstating credentials, licenses, services, locations, disclosures, affiliations, claims, reviews, safety information, eligibility, coverage, or professional qualifications.
For these entities, AI misrepresentation is not only a marketing issue. It can create reputational, legal, compliance, and customer-trust risk.
Empirical stakes in high-stakes domains
The risk in these domains is not hypothetical. A 2026 physician-led red-teaming study published in npj Digital Medicine evaluated four public chatbots on 222 patient-posed primary-care questions and found problematic-response rates ranging from 21.6% to 43.2% and unsafe-response rates from 5% to 13%.35 A 2024 Nature Medicine study using 2,400 real patient cases found that state-of-the-art models diagnose significantly worse than physicians and degrade further when they must gather information themselves rather than receiving it pre-curated.36
These findings sharpen why caveats matter in trust-sensitive selection. Models are systematically overconfident when they verbalize certainty, so the confidence a model expresses is not a reliable signal of the confidence it should hold.37 In a high-stakes category, a caveat may therefore be miscalibrated in either direction — hedging a sound provider or failing to hedge an unsound recommendation. Accurate representation and justified, well-calibrated selection are not marketing niceties in these domains; they are the difference between a recommendation that helps and one that harms.
10. Implications for Businesses
Businesses need to stop asking only: Are we visible? They also need to ask:
- Are we represented accurately?
- Are we selected when relevant?
- Are competitors selected instead?
- Are we trusted enough to be recommended?
- Are we caveated in a way that weakens conversion?
- Are our services clear enough for AI systems to classify?
- Are our locations and service areas unambiguous?
- Are third-party signals strong enough to justify recommendation?
- Are AI systems confusing us with another entity?
- Are we improving or drifting over time?
This requires a new operating discipline: the business must manage its machine-facing identity. The goal is not to game the model. The goal is to make the truth about the entity legible enough to be selected.
11. Implications for AI Systems
AI systems are increasingly making or shaping commercial judgments. They are not neutral mirrors. They are interpretive systems that compress source environments into answers, decide which entities are relevant, generate explanations, and shape user trust — and they may become connected to agents that take action. This makes AI selection behavior a business-critical object of study.
AI selection will also be shaped by commercial arrangements, not legibility alone. In monetized environments, platform incentives, placement economics, and commerce partnerships may influence which entities are surfaced, favored, or transacted with.3839 B2Ai therefore concerns the layer a business can actually influence — the entity's clarity, corroboration, and machine-readable trust. That layer does not guarantee selection, but in a monetized environment it is the precondition for competing at all.
12. Final Thesis
The market is moving from search visibility to AI selection readiness.
SEO remains foundational for Google Search. AI visibility remains useful for understanding where an entity appears. But the deeper commercial question is selection. AI systems now interpret entities, compare them, and decide whether to recommend, caveat, exclude, or act on them — all before a human buyer makes a decision. That creates a new upstream commercial layer:
Recognition is not selection.
Visibility is not trust.
Mention is not recommendation.
Citation is not resolution.
The entities that win in this layer will be the ones AI systems can understand, verify, justify, and select under constraint. The next commercial frontier is not only whether people can find a business. It is whether AI systems can correctly understand it, accurately represent it, and confidently select it. That is the B2Ai thesis.
Appendix A — Canonical Glossary
These definitions are canonical for the B2Ai framework as of v2.6.1. Adjacency notes mark the boundary between a term and its nearest neighbor to prevent conceptual drift.
B2Ai (Business-to-AI)
The upstream commercial layer where businesses must become legible, trustworthy, and selectable to AI systems before they are presented to humans, agents, or downstream decision workflows. A layer upstream of B2B and B2C, not a replacement for either.
SOMAR (Selection, Output Mediation & Authority Resolution)
ToastDeck's resolution discipline: the operational bridge between diagnosis and evidence-bound correction. It identifies whether a selection failure is addressable by the entity, structural to the platform, or caused by unstable authority and representation signals. Proprietary operating methods are outside the scope of this paper.
Machine Path Layer (Layer 0)
The first of the eight operating layers. One layer containing three co-equal pre-selection conditions — Access (0A), Ingestibility (0B), and Discovery (0C) — that together determine whether an entity can enter the machine-mediated decision environment at all.
Access (0A)
The Layer 0 condition testing whether the requesting system is permitted to retrieve the entity's surfaces. Failure mode: Access Exclusion — content present and well-formed, but retrieval refused by an infrastructure layer before content is served. Detected by varying the requesting identity.
Ingestibility (0B)
The Layer 0 condition testing whether substrate legibility holds under real machine retrieval — whether meaning arrives in the response itself or only after a program runs. Failure mode: Substrate Invisibility.
Substrate Legibility
The property of a page or entity surface being machine-readable and usable. The property that Ingestibility checks for.
Substrate Invisibility
The Layer 0B failure mode where the entity may exist and may even be reachable, but the machine cannot meaningfully parse, extract, or use it. Diagnostic signature: raw HTML before script execution returns little or no substantive content. Scoped strictly to 0B.
Discovery (0C)
The Layer 0 condition testing whether the entity surfaces as a candidate at all — whether it can be found, crawled, indexed, or retrieved into the candidate environment before recognition begins.
Discovery Citation
A citation whose function is findability: it helps a machine system find, crawl, index, or retrieve an entity. Operates at Layer 0C. Adjacency: Same surface form as an authority citation, but a different function at a different layer.
Authority Citation
A citation whose function is trust and persuasion: it helps justify why an entity should be trusted, cited, recommended, or selected in an answer. Operates at the higher layers. Adjacency: Discovery citations make an entity findable; authority citations make an entity persuasive.
Recognition
The condition where an AI system correctly identifies what an entity is. Adjacency: Discovery means the entity can be found as a candidate. Recognition means the system correctly understands what the candidate is.
Selection
The condition where an AI system chooses, recommends, ranks, routes to, or relies on an entity under a user constraint or decision context. Adjacency: Authority Resolution is trust evaluation. Selection is the choice made after or during that evaluation. Trusted does not always mean selected.
Selection Instability
The measurable variation in how AI systems recognize, compare, recommend, exclude, justify, caveat, or displace an entity across platforms, prompts, constraints, competitor sets, and time. Adjacency: Stochastic variance is run-level noise. Selection instability is pattern-level signal that changes business meaning, trust position, or competitive framing.
Evidence Class
The rule governing how a finding may be reported, determined by whether the finding is deterministic or probabilistic. Deterministic findings are reported as facts. Probabilistic findings are reported as distributions across runs, orderings, competitor sets, platforms, and time. Adjacency: Not a style preference but a condition of framework integrity.
Perturbation Testing
The diagnostic method for probabilistic findings: hold the entity or decision question fixed while varying candidate order, competitor set, prompt framing, or comparison structure, and observe whether the selection outcome holds. Adjacency: The procedure is deterministic and repeatable; the behavior it reveals is probabilistic and is therefore reported as a distribution, not a single verdict.
Scale Inversion
The condition where a larger, more established, or more visible business is disadvantaged in AI-mediated selection because the system resolves authority through signals that favor smaller, more specific, better-structured, or more machine-legible competitors. Adjacency: Not simple underperformance. It is the inversion of expected advantage when scale or market presence fails to translate into AI selection.
Substitution vs. Selection
The boundary between tasks an AI system can perform directly and decisions where it must choose an accountable external entity. Adjacency: Substitution means the AI does the work. Selection means the AI chooses who or what should do the work.
Appendix B — Research Grounding Map
This appendix maps load-bearing external claims to their verified primary sources. Tier 1 sources anchor an architectural claim; Tier 2 sources support a consequence or mechanism.
| B2Ai Claim | Anchor Source | Tier |
|---|---|---|
| Recognition ≠ Selection (candidate generation vs. ranking) | Covington, Adams & Sargin (2016), RecSys — "classic two-stage IR dichotomy" | Tier 1 |
| Candidate-set composition shapes downstream exposure | Bower et al. (2022), arXiv:2209.05000 | Tier 2 |
| Selection instability / Layer 5 mechanism | Bito, Ren & He (2025), arXiv:2508.02020 — position bias via shuffled-vs-reversed perturbation | Tier 1 (L5) |
| Source Boundary Failure / conflation during synthesis | Onweller et al. (2026), arXiv:2605.06635 — ~42% drop in factual accuracy at scale | Tier 1 (§8) |
| Freshness / Layer 7 — temporal IR field anchor | Campos, Dias, Jorge & Jatowt (2014), ACM Computing Surveys 47(2) Art. 15 | Tier 1 (L7) |
| Freshness / Layer 7 — RAG recency-prior example | Grofsky (2025), arXiv:2509.19376 — single-domain worked example | Tier 2 |
| Caveat Penalty mechanism (calibration / overconfidence) | Xiong et al. (2024), arXiv:2306.13063, ICLR 2024 — systematic overconfidence | Tier 1 (§9) |
| Documented unsafe-advice rates (medical) | Draelos et al. (2026), npj Digital Medicine 9:241 — problematic 21.6–43.2%, unsafe 5–13% | Tier 1 (§9) |
| Degradation toward real practice (clinical) | Hager et al. (2024), Nature Medicine 30(9):2613–2622 | Tier 1 (§9) |
| Perturbation testing / LLM-as-a-Judge position bias | Shi et al. (2025), IJCNLP-AACL — repetition stability, position consistency | Tier 2 |
| LLM-as-a-Judge position-bias mitigation | Zheng et al. (2023), arXiv:2306.05685 / NeurIPS — answer-order swapping | Tier 2 |
| GEO tactic→layer mapping (Authority/Representation) | Aggarwal et al. (2024), KDD, arXiv:2311.09735 — ~30–40% citation visibility increase | Tier 1 (§4) |
| Senior Sitters Club field-study snapshot | VisibilityIQ Full Audit: Senior Sitters Club, May 8, 2026; 24 queries × 4 systems × 5 runs | Primary field source |